
Introduction to Molecules
IM.13. Common Biomolecules
We have seen a number of common "functional groups" from organic chemistry. Functional groups are just collections of atoms that we frequently see, so that it becomes useful to recognize them. Organic compounds, by definition, are carbon-based compounds, usually derived from living things. However, there are a few specific classes of organic molecules that are so common in biology that they are termed "biomolecules". We are going to take a look at them here.
One common group of biomolecules is called "lipids". Lipids can really have lots of different structures. However, the most common type of lipid is an ester. An ester contains an O-C=O unit. Sometimes that group is termed an "ester linkage". We can think of that link as being formed when a carboxylic acid comes together with an alcohol. The carboxylic acid is shown below, in red; the alcohol is in blue. This reaction is often referred to as a condensation reaction because it produces water as a side product. If this reaction were carried out in a glass vessel, you might be able to see moisture condensing on the glass as the reaction proceeds.
Figure IM13.1. A condensation reaction to form an ester.
This carboxylic acid is a particular kind called a fatty acid. It has a long carbon chain. When the alcohol oxygen connects to the carbonyl carbon in the fatty acid, the fatty acid loses its OH group. The alcohol also loses the hydrogen, or proton, from its OH group. That combination of things lost, H + OH, adds up to a water molecule. So every time a fatty acid combines with a alcohol molecule to form an ester linkage, a water molecule is made.
That formation of a water molecule gave rise to an old name for this reaction and others like it. It was called a condensation reaction. That term, "condensation", referred to the water or moisture that was formed during the reaction, like the condensation on the bathroom mirror when you take a shower.
In reality, exactly how these two molecules come together to form one molecule is slightly more complicated than what we are seeing here. At this point, however, this is all you need to know.
The most common kind of lipid in biology is a specific kind of ester called a "glyceride". A glyceride forms between a fatty acid and a glycerol unit. The glycerol unit, in blue, has three hydroxy groups (the OH part). These hydroxy groups are each capable of attaching to the carbonyl carbon in a fatty acid.
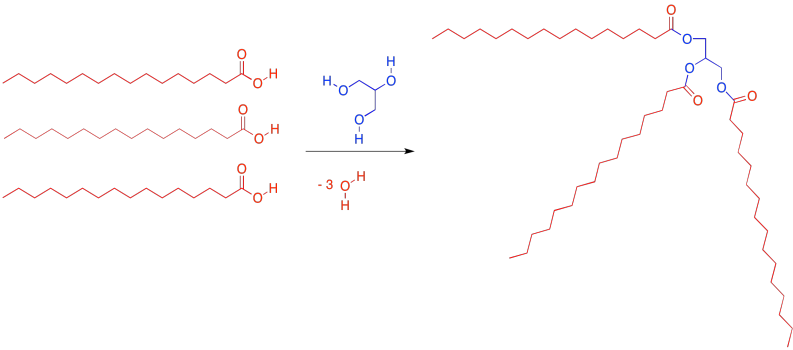
Figure IM13.2. A condensation reaction to form a triglyceride.
When the glycerol oxygen connects to the carbonyl carbon in the fatty acid, the fatty acid loses its OH group, and a proton is lost from the glycerol. So every time a fatty acid combines with a glycerol molecule, a water molecule is made, in addition to the lipid. That's three molecules of water lost, in total, from the original glycerol and fatty acids.
Ester linkages are important partly because they are reversible. Fatty acids can be conveniently stored as glycerides by attaching them to glycerol with ester linkages. However, ester linkages can break open again if water is added. The triglycerides can go back to being glycerol and fatty acids again. Those fatty acids can be used as fuel for the cells. The formation and breaking of ester linkages allows for these processes to be controlled, depending on whether energy is needed right now or should be stored for later.
Incidentally, there are a variety of fatty acids that can form triglycerieds, leading to a diversity of lipids with slightly different properties. There are fatty acids containing carbon chains of various lengths. There are fatty acids with one, two, or three C=C double bonds somewhere in their chains, and others without any. The ones that don't have any double bonds are called saturated fatty acids. Saturated fats are sometimes described by a shorthand notation that tells how long the chain is, followed by a colon, followed by a zero, indicating there are no C=C double bonds.
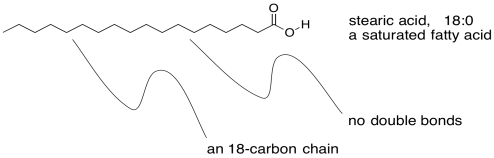
Figure IM13.3. An example of a saturated fatty acid.
Unsaturated fats are sometimes described using a similar shorthand notation, but with a number after the colon indicating how many double bonds are present. That's followed by the symbol Δ, the Greek letter delta, with a supercsript number that tells how far the double bond is from the end of the chain.
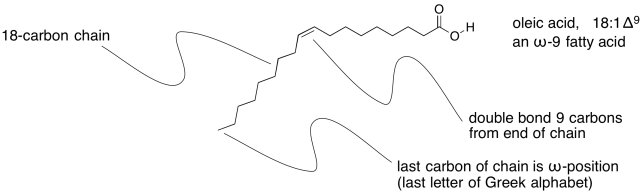
Figure IM13.4. An example of an unsaturated fatty acid.
Sometimes you will hear about omega-3 or omega-6 fatty acids, or some other variation. That's the Greek letter, ω, which is the last letter in the Greek alphabet. It stands for the last carbon in the chain, and the number after it tells you how far the double bond is from the end of the chain.
Problem IM13.1.
Draw the triglycerides that would result in each of the following cases.
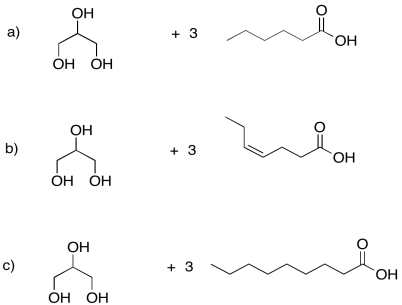
Problem IM13.2.
Phospholipids are important in the formation of cell membranes. In a phospholipid, a phosphate replaces one of the alcohols that would otherwise make a triglyceride. Draw the pjospholipid that would result in the following case.

Problem IM3.3.
Draw the following fatty acids, based on the notation given.
a) linolenic acid, 18:3 Δ3,6,9
b) linoleic acid, 18:2 Δ6,9
c) stearidonic acid, 18:4 Δ3,6,9,12
d) myristic acid, 14:0
e) palmitoleic acid, 16:1 Δ7
f) adrenic acid, 22:4 Δ6,9,12,15
g) arachidonic acid, 20:4 Δ6,9,12,15
h) palmitic acid, 16:0
Carbohydrates are an even more crucial form of fuel storage for the cells. Carbohydrates are carbon-based molecules containing lots of OH groups. Glucose is an example. The drawings below are just a reminder that we usually work with skeletal line structures, like the one on the right, rather than the structures with atom labels, like the one on the left, because things get cluttered pretty quickly in the more explicit drawings. However, if you need to re-draw things with atoms to keep track of where everything is, don't be afraid to do that.
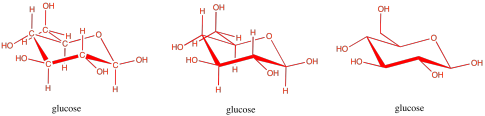
Figure IM13.4. Three ways to draw glucose, a carbohydrate.
Carbohydrates, like fatty acids, are stored in a form in which they are linked together. When needed, they can be unlinked and the individual units, such as glucose, can be sent into energy-generating reactions.
Carbohydrates (or sugars) are connected by "ether linkages". An ether is just a C-O-C unit. In forming an ether linkage, two carbohydrates could come together, attaching one oxygen on one carbohydrate to a carbon on the next, and releasing a water molecule. It's another condensation reaction, like the ester-forming one. This time, a two-carbohydrate pair is formed, called a "disaccharide". The individual carbohydrates are called "monosaccharide"s.

Figure IM13.5. A disaccharide formed via a condensation reaction.
There are lots of carbons that the oxygen atom on a neighbouring carbohydrate might attach to, but the same one is always used. It's the carbon that already has two oxygens attached to it. The carbon in the right-hand corner of the red glucose molecules is an example. As a result, the particular kind of ether linkage between carbohydrates always looks more like C-O-C-O-C. You can see that pattern if you start from the left-hand corner of the blue glucose in the disaccharide, and move leftward across the gap onto the red glucose.
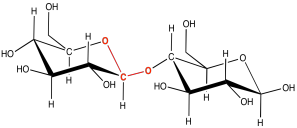
Figure IM13.6. A glycoside linkage.
This sort of double-ether linkage is called a "glycoside linkage" in biochemistry. Don't get it confused with the triglyceride made from a fatty acid plus glycerol. In organic chemistry, this C-O-C-O-C unit is called an "acetal".
These bonds can be used to connect lots of carbohydrates together. Two monosaccharides can be linked to make a disaccharide. A third one would make a trisaccharide. Several of them connected in a chain would be called an oligosaccharide. Many of them connected in a chain would be called a polysaccharide. Other small molecules can be connected in chains, too, although not always by glycoside or acetal linkages. When many small molecules have been connected into one big molecule, we call that molecule a "polymer". That word just means it is made of many things, all put together. A polysaccharide such as cellulose (below) is an example of a biological polymer.
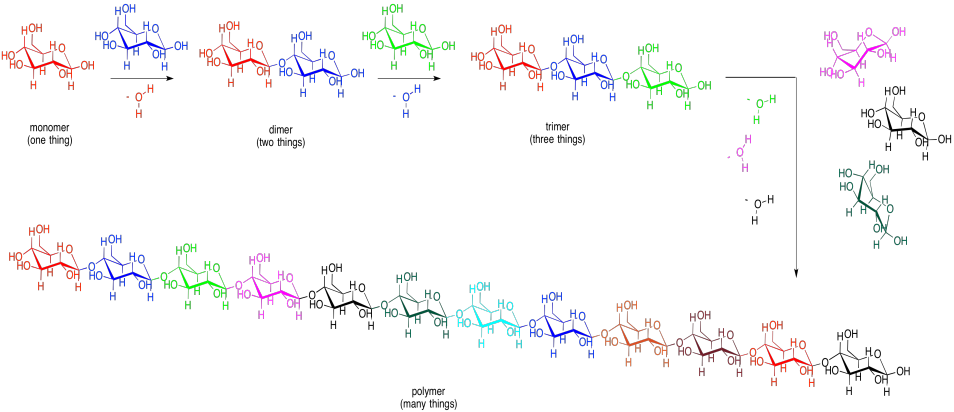
Figure IM13.7. The relationship between monomers, oligomers, and polymers.
Problem IM13.4.
Draw the disaccharides that would result in each of the following cases. Make sure to use the acetal (glycoside) carbon on one molecule; you can link to the primary alcohol (the -CH2-OH group) on the other.
Amino acids are a third general class of biological molecules. Amino acids are important because they are collected together into polymers called proteins. Proteins function like machines; they carry out most of the tasks needed to keep an organism alive.
Amino acids get their name from the fact that they contain two different organic functional groups: an amine (NH2) and a carboxylic acid (CO2H). In order to make proteins, the amine nitrogen on one amino acid connects to the carbonyl carbon (on the C=O group) of the next. Once again, an OH is lost from one molecule and a proton from the other, to make water.

Figure IM13.8. A dipeptide formed via a condensation reaction.
As in lipids, exactly how these two molecules eventually come together is slightly more complicated than that, but this picture is good enough for now. Two amino acids (two monomers) connect together to make one bigger molecule (a dimer) and a water molecule. That dimer is often called a "dipeptide". The bond that has formed between the nitrogen and the carbonyl is called an "amide" bond in organic chemistry, becasue the funtional group formed is called an amide. In biochemistry, this bond is often called a "peptide linkage". It's what holds the two pieces together in a dipeptide.
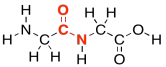
Figure IM13.9. An amide or peptide bond.
As with carbohydrates, amino acids can be linked into long chains. They can make polymers. A polymer of amino acids is called a polypeptide. A protein is just an extremely large polypeptide, in which hundreds of amino acids are connected together in a long chain.
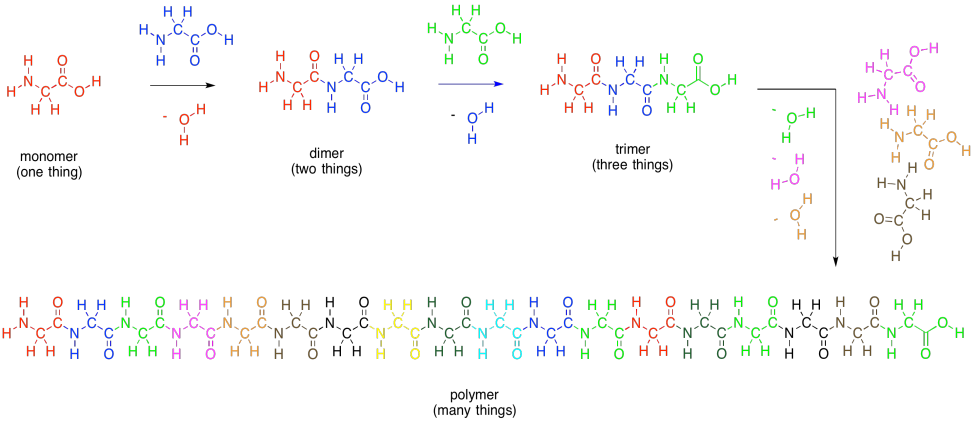
Figure IM13.10. Monomers and polypeptides.
Lipids and carbohydrates are used for storage, among other things, and so it is useful to be able to undo ester linkages and acetal linkages, to get individual fatty acids and carbohydrates again when we need to consume energy. If we get desperate, we could also break down our proteins and polypeptides and get energy from them, but we don't usually use polypeptides for energy storage, because they have so many more valuable roles to play.
In fact, peptide bonds are a little stronger and harder to break than either ester linkages or acetal (glycosidic) linkages. That's because of a resonance contributor to the structure. Notice that oxygen is more electronegative than nitrogen. That oxygen is able to pull the lone pair on the nearby nitrogen closer, forming an N=C π bond that makes the amide stronger and more stable. We still have special enzymes that can break down proteins in our food, but it's not easy.
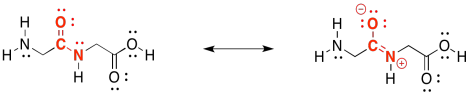
Figure IM13.11. The strong amide bond.
There are a huge variety of proteins that can result from linking amino acids together in this way. That diversity largely results from the fact that lots of different compounds have the same basic amino acid structure, but with modified groups called "side chains". A few examples are shown below.
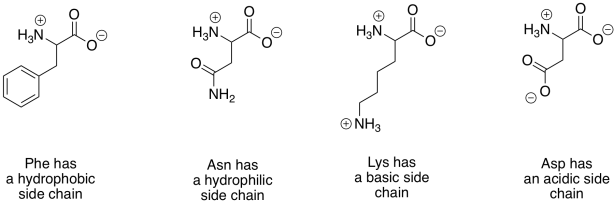
Figure IM13.12. A few examples of biological amino acids.
There are twenty common amino acids in biology. To help organize these compounds, people normally use four different categories that correspond to the properties of the side chains. Two groups of amino acids commonly have charged side chains under biological pH conditions. Acidic side chains give up a proton easily (H+) and become negatively charged as a result; there are two of these, aspartate and glutamate. (Aspartate is just the word for the negatively charged form of aspartic acid; that name is often used because it is shorter than "aspartic acid".) Basic side chains pick up protons easily and are positively charged as a consequence. There are three of them, although only two are usually protonated at neutral pH; the other becomes protonated under slightly more acidic conditions (lower pH).
The polar (or "hydrophilic") amino acids are those that would interact easily with polar water molecules in the cell. You can usually spot them by the presence of strong dipoles in the side chains. Strong dipoles are charge separations between two different atoms that have very differnt electronegativity values. For example, C-O and O-H bonds are polar. In contrast, the non-polar (or "hydrophobic") amino acids have side chains that lack strong dipoles. For example, C-C and C-H bonds are not very polar, because the electronegativity differences between the atoms are small.
Here are all of the common amino acids, arranged according to category, as they would appear when linked in a peptide chain.
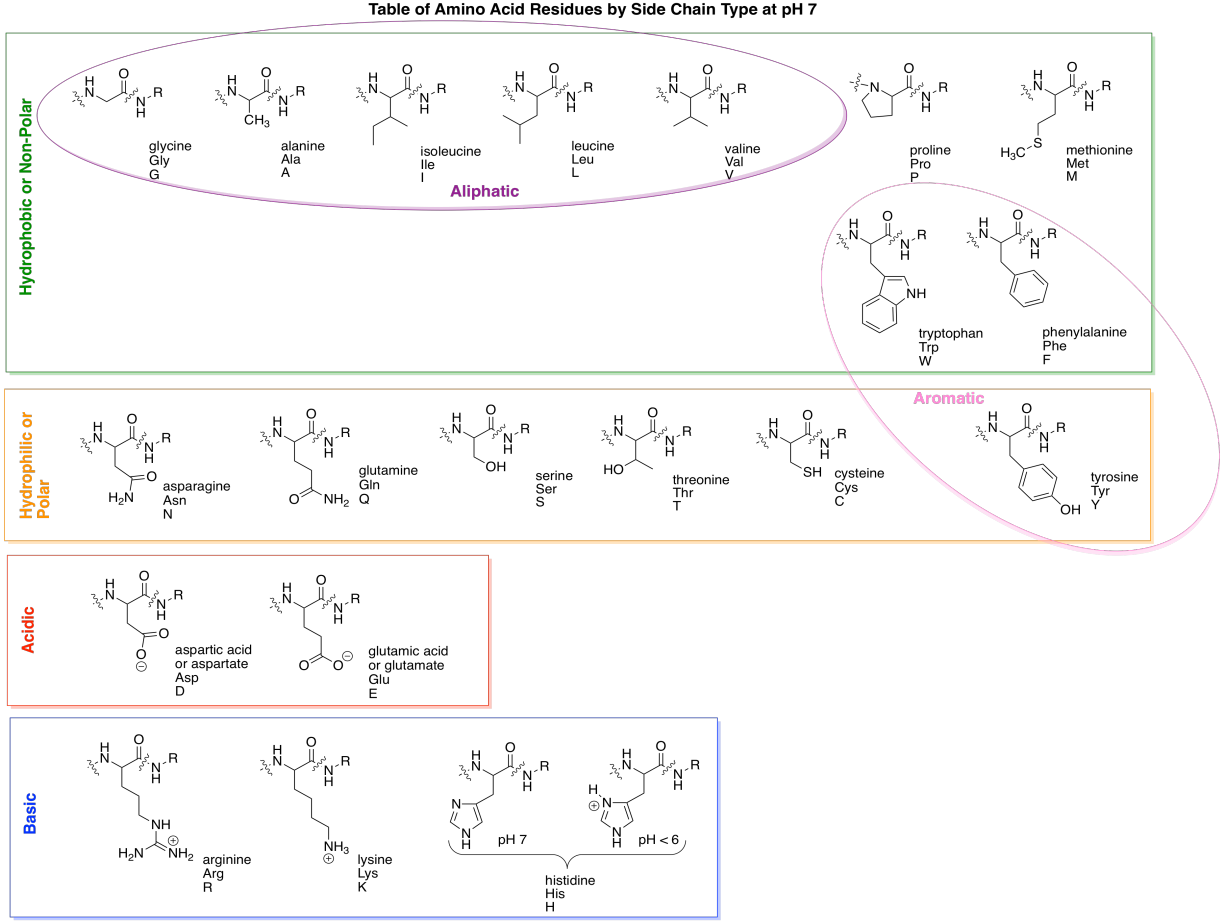
Figure IM13.13. The biological amino acids.
A couple of the amino acid side chains are sort of on the edge in terms of polarity, and some textbooks will place them in a different category. For example, tyrosine has an O-H bond and so is capable of hydrogen bonding with water. That makes it pretty hydrophilic. However, the majority of the side chain contains non-polar C-C and C-H bonds, so sometimes you will see it grouped with hydrophobic side chains.
One more pair of sub-groups you will sometimes see are the aromatic and aliphatic amino acids. Aliphatic ones contain carbon chains, but not other functional groups, whereas aromatics contain "aromatic rings" such as benzene. Aromatics are usually six-membered rings with double bonds alternating all the way around. They are flat groups that can stack on top of each other and sometimes that property can be important.
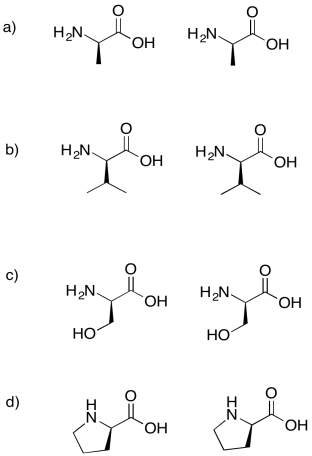
Problem IM13.5.
Draw the dipeptides that would result in each of the following cases.
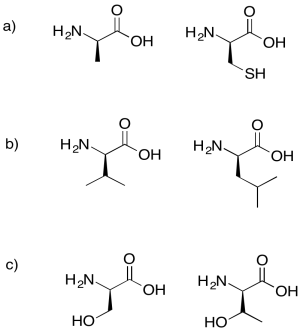
Problem IM13.6.
Draw the possible dipeptides that would result in each of the following cases.
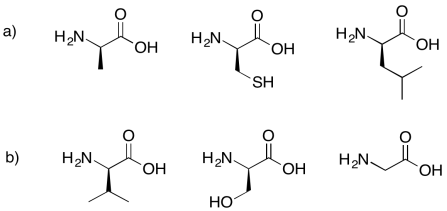
Problem IM13.7.
Draw the possible tripeptides that would result in each of the following cases.
Possibly the most well-known biomolecules are the nucleic acids, DNA and RNA. These compounds are examples of co-polymers. Like complex carbohydrates, they are composed of individual molecules that have become covalently bonded to each other to form polymer chains. However, DNA and RNA always contain three different types of monomer: bases, sugars, and phosphates.
The sugar is the part that gives rise to the D in DNA or the R in RNA. Ribose, found in RNA, is a five-membered ring with oxygens on each carbon, mostly as OH groups. Deoxyribose, found in DNA, is almost identical, but is missing one OH group.
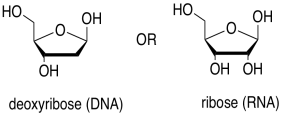
Figure IM13.14. The sugar building blocks of nucleic acids.
One of four different bases can attached to this sugar in DNA, and one of four different bases can be attached to this sugar in RNA. Three of those bases can be found in either molecule: adenine, cytosine, and guanine. The fourth is unique to either DNA (thymine) or RNA (uracil).
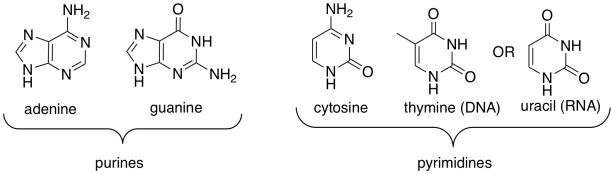
Figure IM13.14. The base building blocks of nucleic acids.
These five bases (so called because, like the basic amino acid side chains, they can pick up protons) fall into two categories. Pyrimidines (peer-IM-id-eens) each contain a six membered ring. Purines (PURE-eens) contain both a six-membered and a five-membered ring. These categories are important because of "base-pairing"; that's when a strand of DNA can bind to a complementary strand via hydrogen bonding between a base on one strand and another base on another. In base-pairing, a purine always binds to a pyrimidine partner: guanine to cytosine, and adenine to thymine (in DNA) or uracil (in RNA).
The bases are covalently bonded to sugars at the glycoside position - that same place sugars link to each other in carbohydrates. The new bond is called a N-glycoside bond. The new compound is called a nucleoside.
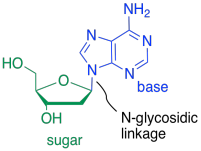
Figure IM13.15. An example of a nucleoside: adenosine.
The third type of molecule that comes together to form the nucleic acid co-polymer is a phosphate. It becomes covalently bonded to the primary alcohol group at the other end of the ring from the base. The bond between the phosphate and the sugar is called a phosphate ester bond. The new compound is called a nucleotide.
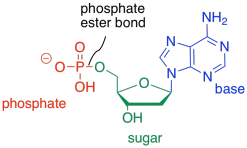
Figure IM13.15. An example of a nucleotide: adenosine monophosphate.
To form a co-polymer, another phosphate ester bond forms with the sugar of another nucleotide. The phosphate between the two sugars is sometimes called a phosphodiester linkage, meaning that the phosphate is forming two esters at once to bridge the two sugars.
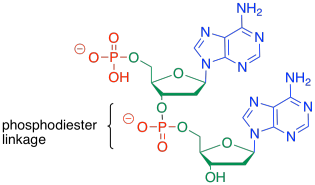
Figure IM13.16. Two nucleosides bound by a phosphate linkage.
Sometimes, people will refer to the 3'-end or the 5'-end of a nucleic acid strand. Those numbers refer to a system of numbering the carbons in the sugars. If you are talking about the end of the DNA chain that is closest to carbon number 3 of the nearest sugar, you are talking about the 3' end.
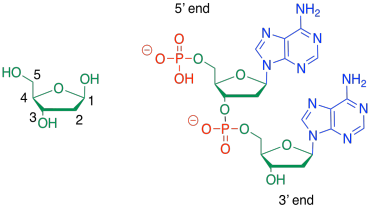
Figure IM13.17. Organizational numbering in nucleic acids.
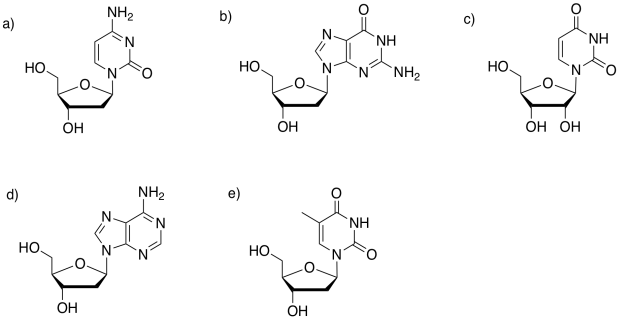
Problem IM13.8.
Identify the base in each of the following nucleosides.
This site was written by Chris P. Schaller, Ph.D., College of Saint Benedict / Saint John's University (retired) with contributions from other authors as noted. It is freely available for educational use.

Structure &
Reactivity in Organic, Biological and Inorganic Chemistry
by Chris Schaller is licensed under a
Creative Commons Attribution-NonCommercial 3.0 Unported License.
Send corrections to cschaller@csbsju.edu
Navigation:
Back to Structure & Reactivity Web Materials