Last Update: 04/17/2002
Structure of DNA
DNA is a polymer, consisting of monomers call nucleotides. The monomer contains a simple sugar (deoxyribose), a phosphate group, and a cyclic organic group that is a base (not an acid). Only four bases are used in DNA, which we will abbreviate, for simplicity, as A, G, C and T. The polymer consists of a sugar - phosphate - sugar - phosphate backbone, with 1 base attached to each sugar molecule. DNA can exist as single (with one sugar-phosphate backbone), double-stranded (with two sugar-phosphate backbones which bind to each other through their bases) , or mixed forms. It is actually a misnomer to call dsDNA a molecule, since it really consisted of two different, complementary strands held together by IMF's. However, most people talk about a molecule of dsDNA, and so will I. dsDNA varies in length (number of sugar-phosphate units connected), base composition (how many of each set of bases) and sequence (the order of the bases in the backbone. the links links below will help you understand the properties of DNA.
An Introduction to DNA and RNA
![]() Chime
Molecular Modeling: double-stranded
DNA.
Chime
Molecular Modeling: double-stranded
DNA.
![]() Chime
Molecular Modeling: the
Genetic Code
Chime
Molecular Modeling: the
Genetic Code
![]() Chime
Molecular Modeling::DNA
Strands and Backbone
Chime
Molecular Modeling::DNA
Strands and Backbone
![]() Chime
Molecular Modeling: DNA:
Ends and Parallelisms
Chime
Molecular Modeling: DNA:
Ends and Parallelisms
Structure of a chromosome
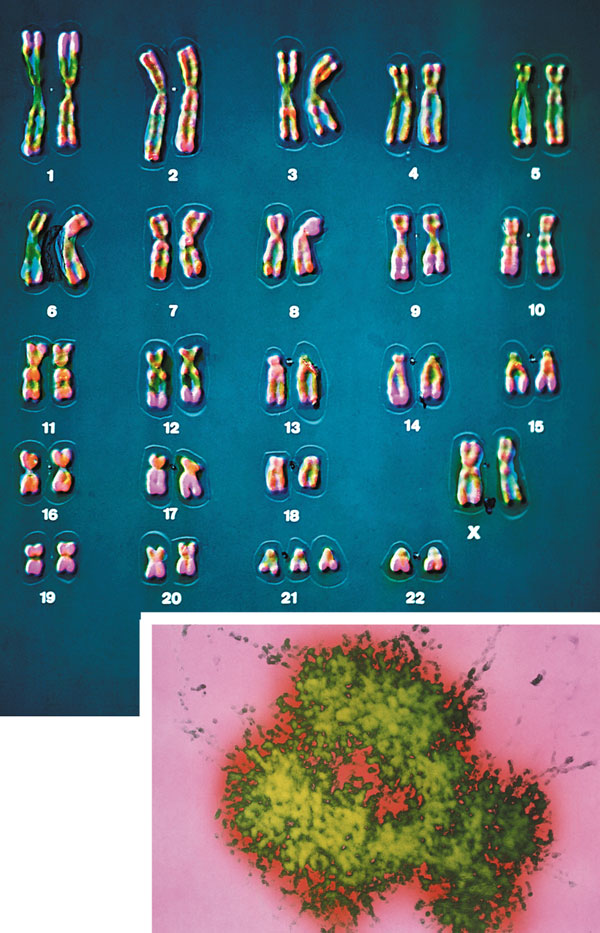
Most people have seen pictures of chromosomes viewed through microscopes. Check out this amazing picture of a chromosome taken form Scientific American, September, 1995.
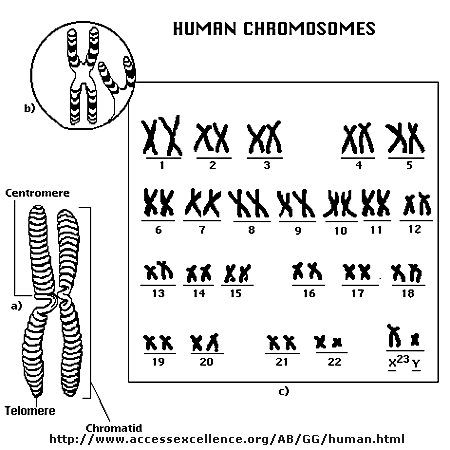
Chromosomes consist of one dsDNA molecule. Each somatic (body) cell of your body has 23 pairs of chromosomes, one member of each pair contributed by your mother and the other by your father. (In germ cells - eggs and sperm - there are 23 individual chromosomes, not chromosome pairs.) One pair are the sex chromosomes, which can come in two forms, X and Y. A pair of X's gives a female, and an XY results in a male.
Human Chromosomes (with an extra copy of Chromosome 21, which causes Down syndrome) - Nature 405, 283 - 284 (2000)
The human genome has about 3 billion base pairs of DNA. Therefore, on average, each single chromosome of a pair has about 150 million base pairs, which consists of one molecule of DNA and lots of proteins bound to it. dsDNA is a highly charged molecule, and can be viewed, to a first approximation, as a long rod-like molecule with a large negative. charge. This very large molecule must somehow be packed into a small nucleus. The packing problem is solved by coiling DNA and packing it with proteins, which usually have a net positive charge. The chromosomes are usually dispersed within the nucleus and are not visible with an ordinary microscope. When the cell is ready to divide, the DNA in the chromosomes replicates, and the chromosomes condense in a fashion that they are visible (when stained) using an ordinary microscope. At this point the chromosomes can be stained with a variety of stains (hence the name chromosomes), some of which bind differentially to different chromosomes. The different chromosomes can hence be distinguished by their size, shape, and dye-binding properties.
The standard picture of a chromosome with which you are familiar, including the one shown above, is actually one chromosome of a pair that has just replicated!. One of the chromosomes will stay will the mother cell, and the other will go to the daughter cell. These two chromosomes which are aligned and appear joined at their centers are called sister chromatids. These large DNA/protein complexes must be further packaged in the nucleus, as shown in the "Carl Saganesque" reducing view of the chromosome, a double stranded DNA molecule winds around a core of proteins.
Fun DNA Facts to Know and Tell
Central Dogma of Biology:
DNA is the carrier of genetic information in organisms. What does that mean? Large molecules in organism can have many functions: they can provide structure, act as catalyst for chemical reactions, serve to sense changes in their environment (leading to immune responses to foreign invaders and to neural responses to stimuli such as light, heat, sound, touch, etc) and provide motilty. DNA really does none of these things. Rather you can view it as an information storage system. The information must be decode to allow the construction of other large molecules. The other molecules are usually proteins, another class of large polymers in the body. Chromosomes are located in the nucleus of a cell. DNA must be duplicated in a process called replication before a cell divides. The replication of DNA allows each daughter cell to contain a full complement of chromosomes.
Animation of Replication: requires Hypercosm plugin (available when select link)
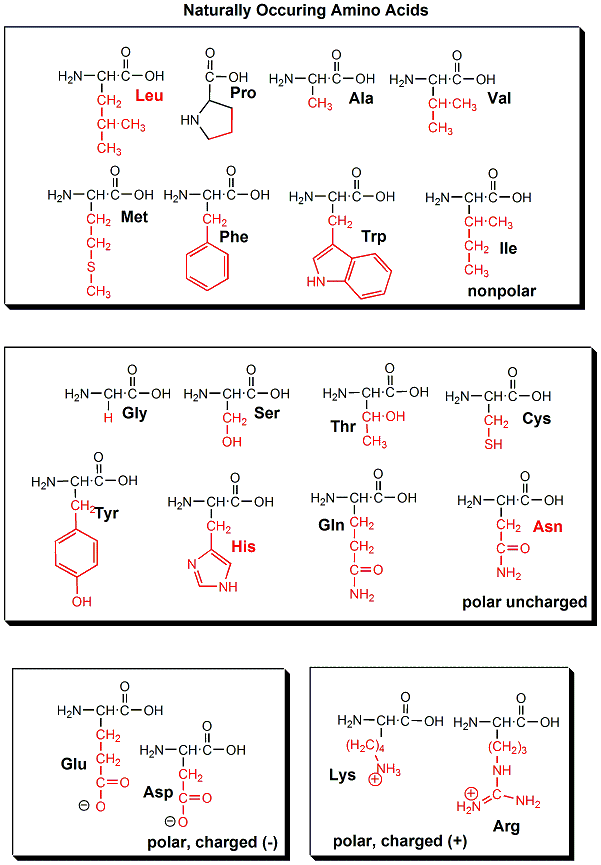
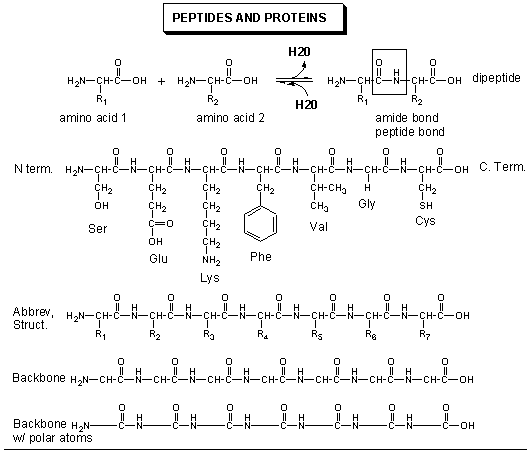
The actual information in the DNA of chromosomes is decoded in a process called transcription through the formation of another nucleic acid, ribonucleic acid or RNA. The RNA, made by the enzyme RNA polymerase, is complementary to one strand of the DNA. RNA differs from DNA in that RNA contains a ribose, not deoxyribose, sugar in its backbone. In addition, RNA lacks the base T. It is replaced, instead, with the base U, which is complementary to A (as T is complementary to A in DNA). The RNA formed acts as a messenger, which passes from the nucleus into the cytoplasm of the cell. In fact, this type of RNA is often called messenger RNA, mRNA. The information from the DNA, now in the form of a linear RNA sequence, is decoded in a process called translation, to form a protein, another biological polymer. The monomer in a protein is called an amino acid, a completely different kind of molecule than a nucleotide. There are twenty different naturally occurring amino acids that differ in one of the 4 groups connected to the central carbon. In an amino acid, the central (alpha) carbon has an amine group (RNH2), a carboxylic acid group (RCOOH), and H, and an R group attached to it. With four different groups attached to the central carbon, all amino acis (except Glycine) are chiral and exists in enantiomers or mirror image forms. Only one of the mirror image is found in proteins.
20 Naturally Ocuring Amino Acids - Molecular Models: Notice the common blue and red groups in al amino acids. Notice the different "R" groups pointing down in each figure.
The monomers come together to form a long chain called a protein. The linear sequence of a protein can be depicted in many ways, as shown below.
In contrast to the complementarity of DNA and RNA (1 base in RNA complementary to 1 base in DNA), there is not a 1:1 correspondence between a base (part of the monomeric unit of RNA) in RNA to the monomer in a protein. After much work it was discovered that a contiguous linear sequence of 3 nucleotides in RNA is decoded by the molecular machinery of the cytoplasm with the result that 1 amino acid is added to the growing protein. Hence a triplet of nucleotides in DNA and RNA have the information for 1 amino acid in a protein. That there was not a 1:1 correspondence between nucleotides in nucleic acids and amino acids in proteins was evident long ago since there are only 4 different DNA monomers (with A, T, G, and C) and 4 different RNA monomers (with A, U, G, and C) but there are 20 different amino acid monomers that compose proteins.
Now, it turns out that not all the information in the DNA sequence of a organism encodes for a protein. In fact only about 2% of the 3 billion base pairs seem to be transcribed into RNA which can be translated into protein. The function of the rest of the DNA is at present uncertain. How does the molecular machinery of the cell know which part of the DNA encodes for proteins. It turns out that there are unique DNA sequences at the beginning and end of the part of the DNA sequence that codes for a protein. Proceed down the DNA of a chromosome and suddenly you come to those signals, which are recognized by the cells machinery. A complementary RNA is made from that section, and the complementary RNA is then decoded into a single protein. Continue further down the DNA sequence and another such coding sequence is found, which can be transcribed into a mRNA, which then can be translated into another unique protein. In all there are about 30-40 thousand such sections of DNA in all the chromosomes that encode the information for 30-40 thousand unique proteins. These unique coding sections of DNA that ultimately are transcribed into unique mRNA which are translated into unique proteins are called genes. For issue of simplicity, we conclude that one gene has the information for one protein. Each of the protein differ from each other in both length, and the specific sequence of amino acids in the protein. The DNA is indeed the blueprint of the cell. What determines the actual characteristics of the cells are the actual proteins that are made by the cell.
Not only must DNA be transcribed into DNA, but the genetic information in the DNA must be replicated before a given cell divides, so that the daughter cells both contain the same genetic information. In replication, the dsDNA separate, and an enzyme, DNA polymerase, makes complimentary copies of each strand. The two resulting dsDNA strands separate to different daughter cells during division. The process where by DNA is replicated when cells divide, and is transcribed into RNA which is translated into protein is called the Central Dogma of Biology. (disregard tRNA, rRNA, and snRNA in the preceding web link)
As mentioned above, each amino acid is specified by a particular combination of three nucleotides in RNA. The three bases are called a codon. The Genetic Code consists of a chart which shows what triplet RNA sequence or codon in mRNA codes for which of the 20 amino acids. One of the codon codes for no amino acids and serves to stop the synthesis of the protein from the mRNA sequence. The genetic code is shown below:
GENETIC CODE
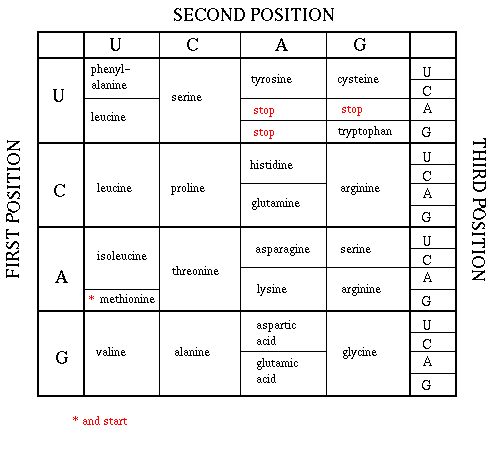
Determining the protein sequence from a DNA sequence.
For a given gene, only one strand of the DNA serves as the template for transcription. An example is shown below. The bottom (blue) strand in this example is the template strand, which is also called the minus (-) strand,or the sense strand. It is this strand that serves as a template for the mRNA synthesis. The enzyme RNA polymerase sythesizes an mRNA in the 5' to 3' direction complementary to this template strand. The opposite DNA strand (red) is called the coding strand, the nontemplate strand, the plus (+) strand, or the antisense strand.
The easiest way to find the corresponding mRNA sequence (shown in green below) is to read the coding, nontemplate, plus (+), or antisense strand directly in the 5' to 3' direction substituting U for T. Find the triplet in the coding strand, change any T's to U's, and read from the Genetic Code the corresponding amino acid that would be incorporated into the growing protein.
5' T G A C C T T C G A A C G G G A T G G A A A G G 3' 3' A C T G G A A G C T T G C C C T A C C T T T C C 5'
5' U G A C C U U C G A A C G G G A U G G A A A G G 3'
A Nucleotide to Protein Converter
Proteins
In contrast to the linear polymers of DNA and RNA, proteins (linear polymers of amino acids) fold in 3D space to form structures of unique shapes. Each unique protein sequence (of a given length and sequence of amino acids) folds to a unique 3D shape. Hence there are about 30-40 thousand proteins of different shapes in humans. Not only do proteins have unique shapes, but they also have unique nooks and crannies and pockets which allow them to bind other molecules. Binding of other molecules to proteins or DNA initiates or terminates the function of the protein or nucleic, much like an on/off switch. The example below show different protein structures, some of which have small molecules or large molecules (like DNA) bound to them. Some common motiffs are found within the 3D structure of the protein. The include alpha helices and beta sheets. These are held together by H-bonds between the slightly positive H on the N in the protein backbone and a slightly negative O further away on the protein backbone. In the Chime models below, use the mouse controls to rotate the molecule. (Also shift L-mouse click will change the size of the molecule). Click on the command in the right hand frame to change the rendering of the proteins. The cartoon view allows a simple way to interpret the overall structure of the main chain.
![]() Alpha
Helices of Proteins
Alpha
Helices of Proteins
![]() Twisted
Beta Sheets of Proteins
Twisted
Beta Sheets of Proteins
![]() Beta
Barrel of Proteins
Beta
Barrel of Proteins
(a protein enzyme that detoxifies the body of toxic oxygen byproducts and which high level of the protein have been associated with longer life spans.)
![]() TATA
Binding Protein - a protein that binds DNA
TATA
Binding Protein - a protein that binds DNA
![]() RU486:Progesterone
Receptor - the protein that binds RU486
RU486:Progesterone
Receptor - the protein that binds RU486
Mutations
If the DNA sequence in a coding region becomes changed, the resulting mRNA will also be changed, which will lead to changes in the protein sequence. These changes might have no effect and be silent, if the change in the protein does not affect the folding of the protein or its binding to another important molecule. However, if the changes affects either the folding or the binding region, the protein may not be able to peform its usual function. If the function was to put on break on cell division, the result might lead the cell to become a cancerous. Likewise, if the normal protein had a role in causing the cell to die after its intended life span, the cell with the mutant protein might not die and more likely become a tumor. The opposite scenarios could happen leading the cell to a premature death.
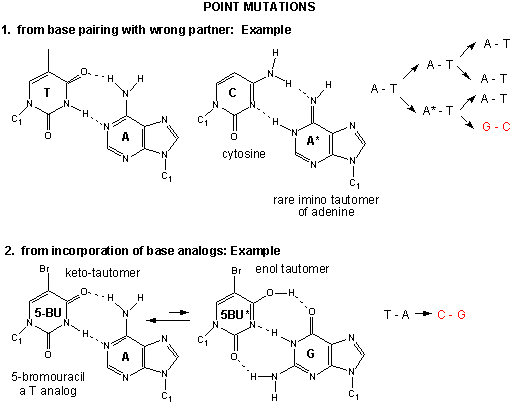
Point mutations: From bad luck and nucleotide analogs
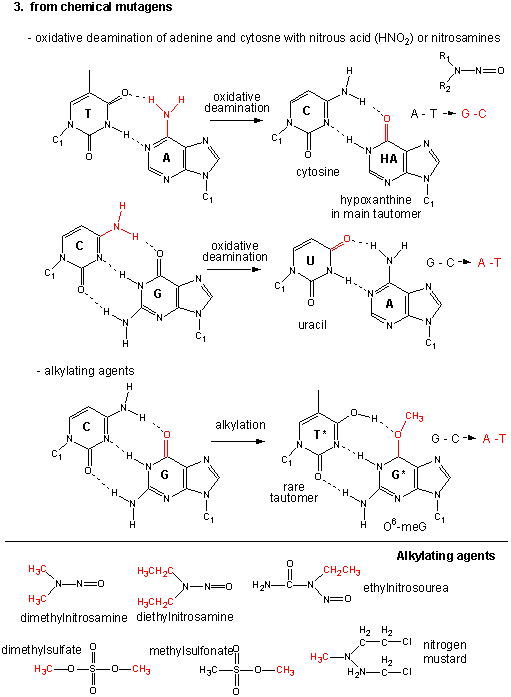
Point mutations: From chemical mutagens
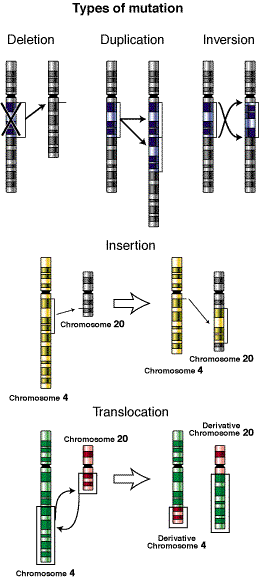
Large mutations: Deletions, insertions, duplications, and inversions
More on Genes
Toa first approximation, we decided that genes are continuous segments of DNA that are transcribed into a single continuous strand of RNA which is translated into a single protein. The human genome appears to have about 40,000 genes, which then would imply that 40,000 proteins could be made. But consider this. We have an immune system that can recognize almost any foreign molecules thrown at it. One immune response is the production of antibodies which are proteins that recognize and bind to foreign molecules. How many different antibody molecules can we make. Hopefully the number is greater than 40,000, but how our limited genome encode for all of them as well as the other proteins required. One solution to the problem would be if more than one protein can arise from one DNA gene sequence. This is a common occurrence in nonbacterial cell. How does this happen?
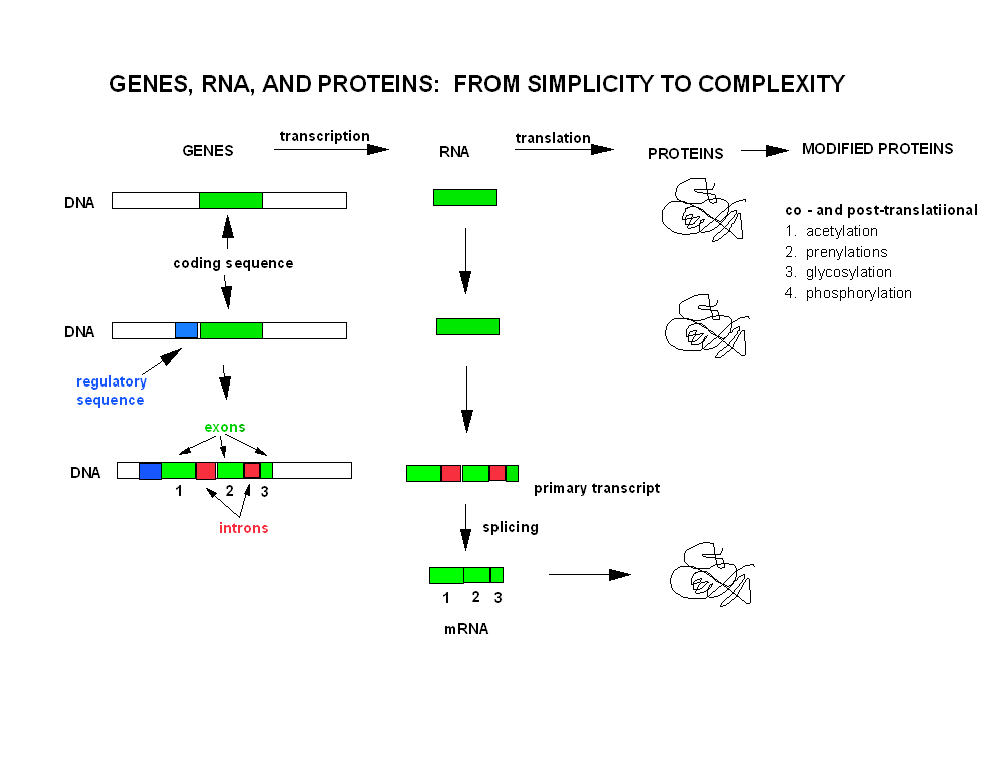
One mechanisms arises from the fact that a single "gene" is divided into coding (exons) and nocoding intervening (intron) sequences. The entire gene, including introns, is transcribed into RNA. The the coding parts of the RNA must be sliced together, with removal of the noncoding RNA sequences, to give the mature RNA. If different exons in a given "gene" are spliced together to form different "mature" RNA molecules, then different proteins could arise from the same initial "gene" sequence.
Genes: From Simplicity to Complexity
Genes and Disease
A Map showing gene involvement in specific human diseases. Click on the chromosome number
DNA: Mastery of a Language
The four letter alphabet (A, G, C, and T) that makes up DNA represents a language that when transcribed and translated leads to the myriad of proteins that make us who we are as a species and as individuals. Let's continue with the metaphor that DNA is a language. To master that language, as with any other language, we need to be able to read, write, copy, and edit that language. If you were using a word processor to find one line in a hundred page document, or one article from one book out of the Library of Congress or of the Manhattan phone book, you would also need a way to search the large print base available. You might want to compare two different copies of files to see if they differ from each other. From this online discussion, you will learn how modern scientists read, write, copy, edit, search, and compare the language of the genome. These abilities, acquired over the last twenty years, have revolutionized our understanding of life and have given us the potential to alter, for good or evil, life itself.
MANAGING DNA
DNA in human chromosomes exists as one long double stranded molecule. It is too long to physically study and manipulate in the lab. Using a battery of enzymes, the DNA of chromosomes can be chemically cleaved into smaller fragments which are more readily manipulable. (Similar techniques are used to sequence proteins, which require overlapping polypeptide fragments to be made.) After the fragments have been made, they must be separated from each other in order to study them. DNA fragments can be separated on the basis of some structural feature that differentiates the fragments from each other. The best way to separate the fragments from each other is to base the separation on the actual size of the fragment by separating the molecules based on their charge using a technique called electrophoresis on an agarose or polyacrylamide gel.
A carbohydrate extract called agarose is made from algae. Water is added to the extract, which is then heated. The carbohydrate extract dissolves in the water to form a viscous solution. The agarose solution is poured into a mold (like warm jello) and is allowed to solidify. A plastic comb with wide teeth was placed in the agarose when it was still liquid. When the agarose is solid, the comb can be removed, leaving in its place little wells. A solution of DNA fragments can be placed in the wells. The agarose slab with sample is covered with a buffer solution and electrodes placed at each end of the slab. The negative electrode is placed near the well end of the agarose slab while the positive electrode is placed at the other end. If a voltage is applied across the agarose slab, the negatively charged DNA fragments will move through the agarose gel toward the positive electrode. This migration of charged molecules in solution toward an oppositely charged electrode is called electrophoresis. Pretend you are one of the fragments. To you the gel looks like a tangle cobweb. You sneak your way through the openings in the web as you move straight forward to the positive electrode. The larger the fragment, the slower you move because it is hard to get through the tangled web. Conversely, the shorter the fragment, the faster you move. Using this technique and its many modifications, oligonucleotides differing by just one nucleotides can be separated from each other. As you read the rest of this tutorial, you will come to the profound realization that all of these techniques are based in some way on the simple principle that small oligonucleotides interact with DNA through intermolecular forces!
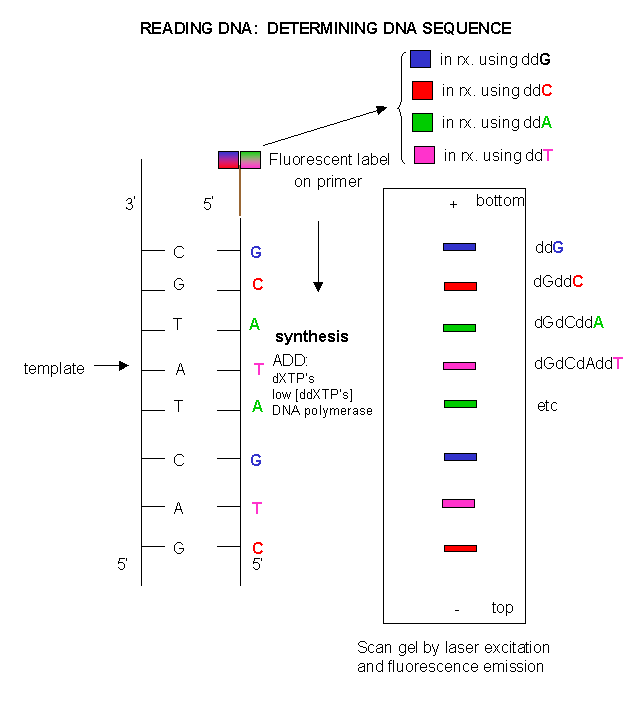
A. Reading DNA:
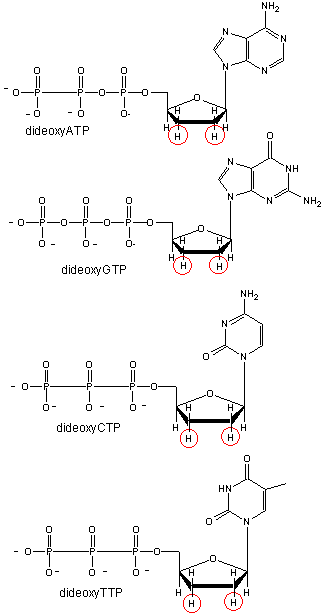
To determine the sequence of a single stranded piece of DNA, the complementary strand is synthesized using an enzyme, DNA polymerase. The enzyme is added to the DNA along with the 4 monomers that are used to make DNA with A's, C's, G's, and T's. The monomers are called dATP, dCTP, dGTP, dTTP. In addition, small amounts of dideoxyATP (ddATP) are added to one reaction tube. Likewise, small amounts of dd CTP, ddGTP, and ddTTP are added to three other reaction tubes. In the tube with dATP and small amounts of ddATP, the dATP and ddATP attach randomly to the growing 3' end of the complementary stranded. If ddATP is added no further nucleotides can be added after since its 3' end has an H and not a OH. That's why they call it dideoxy. The new chain is terminated.. If dATP is added, the chain will continue to grow until another A needs to be added. Hence a whole series of discreet fragments of DNA chains will be made, all terminated when ddATP was added. The same scenario occurs for the other 3 tubes, which contain dCTP and ddCTP, dTTP and ddTTP, and dGTP and ddGTP respectively. All the fragments made in each tube will be placed in separate lanes for electrophoresis, where the fragments will separate by size. More modern methods allow the use of differ fluorescent tags to be added to synthesized fragments ending in G, T, A, or C.
DNA sequencing using different fluorescent primers for each ddXTP reaction
The Human Genome Project (a public consortium) and the private initative by Celera, have recenty announced that they have completed a working draft of the entire sequence of the human genome. The Human Genome Project is sequencing DNA collected from a number of volunteers whose identity will remain secret to protect their privacy.Completing the DNA sequence of the human genome will provide scientists with a tool for genetics akin to the Periodic Table of the Elements. Instead of 100 chemical elements, though, the genome contains about 30-40 thousand elements, the human genes. Once you have the table of the elements, you can begin to figure out how the genes function, how genes interact, and how they contribute to common disorders. Other projects are determining the entire sequences of many infectious bacteria, and from higher organisims including fruit flys, round worms, mice, and chimpanzees, our closest genetic relative (98.6% identical).

B. Writing DNA:
Oligonucleotide can be synthesized on a solid bead. By adding one nucleotide at a time, the sequence and length of the oligonucleotide can be controlled.
C. Copying DNA:
Several methods exists for copying a sequence of DNA millions of times. Most methods make use of plasmids (which are found in bacteria) and viruses (which can infect any cell). The DNA of the plasmid or virus is engineered to contain a copy of a specific DNA sequence of interest. The plasmid or virus is then reintroduced into the cell where amplification occurs.
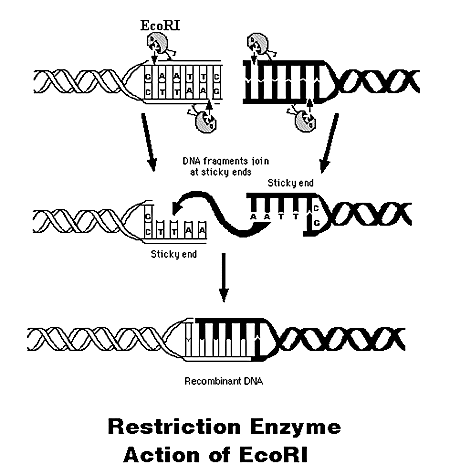
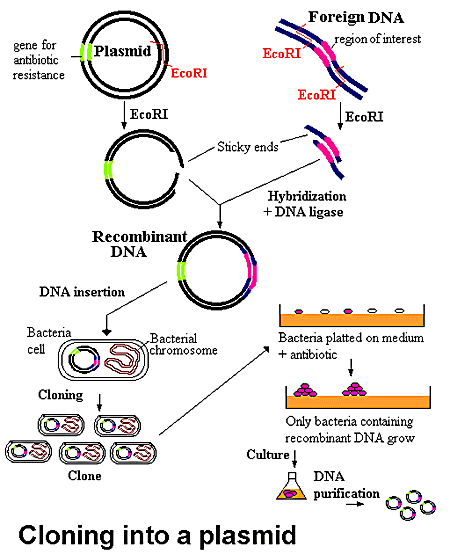
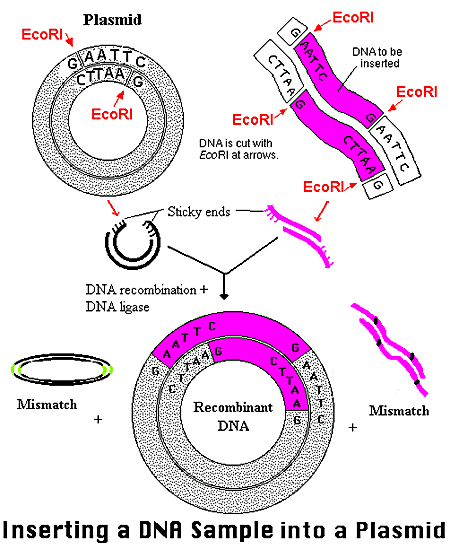
Initially, a DNA containing a gene is cut at specific places with an enzyme called a restriction endonuclease, or restriction enzyme for short. The enzyme, which you can think of a molecular scissors, doesn't cleave DNA any old place, but rather at "restricted" places in the sequence. The restriction endonuclease must cleave both strands of dsDNA. It can cut the strands cleanly to leave blunt ends, or in a staggered fashion, to leave small tails of ssDNA. Multiple such sites exist at random in the genome. The gene of interest must be flanked on either side by such a sequence. The same enzyme is used to cleave the plasmid or virus DNA.
Cleaving DNA with the Restriction Enzyme EcoR1
The foreign fragment of DNA can then be added to the plasmid or viral DNA as shown to make a recombinant DNA molecule. This technique of DNA cloning is the basis for the entire field of recombinant DNA technology.
Cloning a Restriction Fragment into a Plasmid
Animation of Gene Splicing - Requires Hypercosm Plugin (available when select link)
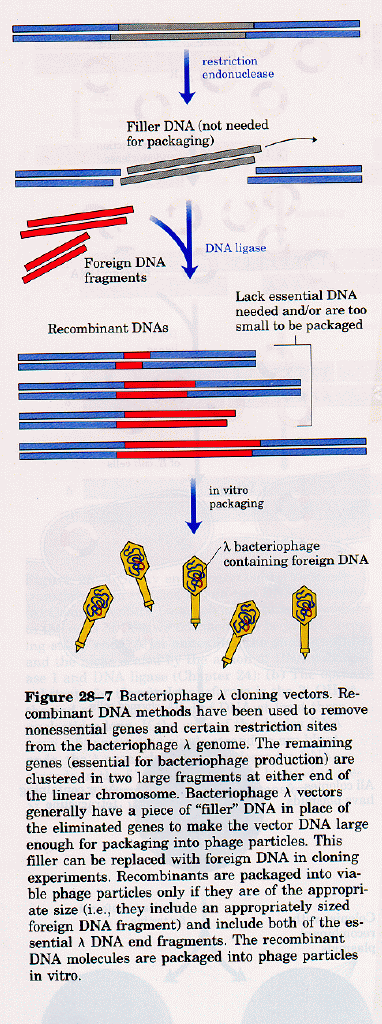
The plasmid can be added to bacteria, which take it up in a process called transformation. The plasmid can be replicated in the bacteria which will copy the DNA fragment of interest. A similar method can be used to copy DNA in which the foreign fragment is recombined with the DNA of bacteriophage , a virus which infects bacteria like E. Coli. The recombinant DNA can be packaged into actual viruses, as shown below. When the virus infects the bacteria, it instructs the cells to make millions of new viruses, hence copying the foreign fragment of interest.
FIGURE: DNA CLONING AND COPING IN BACTERIA VIRUS: LEHNINGER, PG 992, FIG 28.7
Sometimes, "cloning" or copying a fragment of DNA is not what an investigator really wants. One such possible method exists in which you start with the actual mRNA for a protein of interest. In this technique, a dsDNA copy is made from a ss-mRNA molecule. Such dsDNA is call cDNA, for complementary or copy DNA. This can then be cloned into a plasmid or bacteriophage vector and amplified as described above.
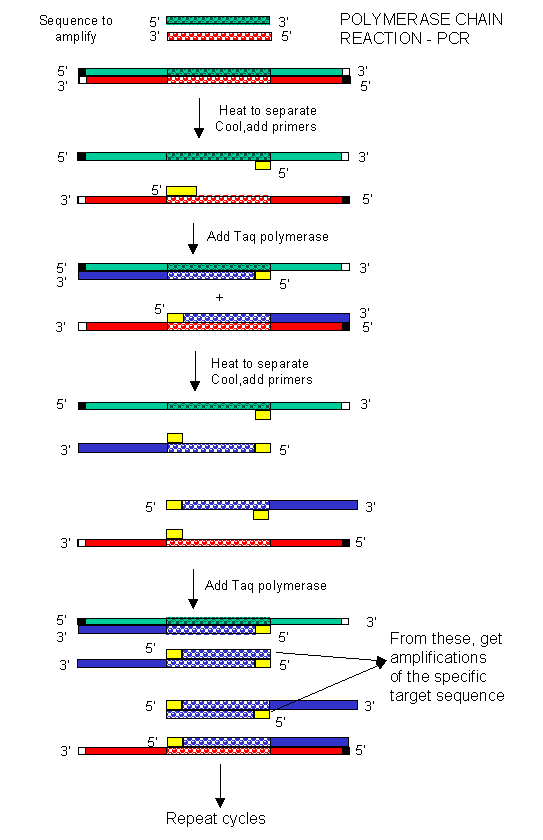
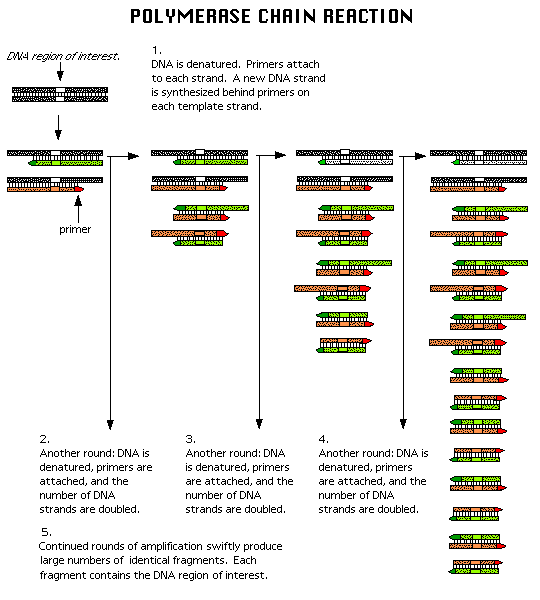
In the mid 80's a new method was developed to copy (amplify) DNA in a test tube. It doesn't require a plasmid or a virus. It just requires a DNA fragment, some primers (small polynucleotides complementary to sections of DNA on each strand and straddling the section of DNA to be amplified. Just add to this mixture dATP, dCTP, dGTP, dTTP, and a heat stable DNA polymerase from the organism Thermophilus aquaticus (which lives in hot springs), and off you go. The mixture is first heated to a temperature which will cause the dsDNA strands to separate. The temperature is cooled allowing the primers to bind to the ssDNA. The heat stable Taq polymerase (from Thermophilus aquaticus) polymerizes DNA from the primers. The temperature is raised again, allowing dsDNA strand separation. On cooling the primers anneal again to the original and newly synthesized DNA from the last cycle and synthesis of DNA occurs again. This cycle is repeated as shown in the diagram. This chain reaction is called the polymerase chain reaction (PCR). The target DNA synthesized is amplified a million times in 20 cycles, or a billion times in 30 cycles, which can be done in a few hours.
FIGURE: COPYING DNA IN THE TEST TUBE - THE POLYMERASE CHAIN REACTION (PCR)
D. Editing DNA
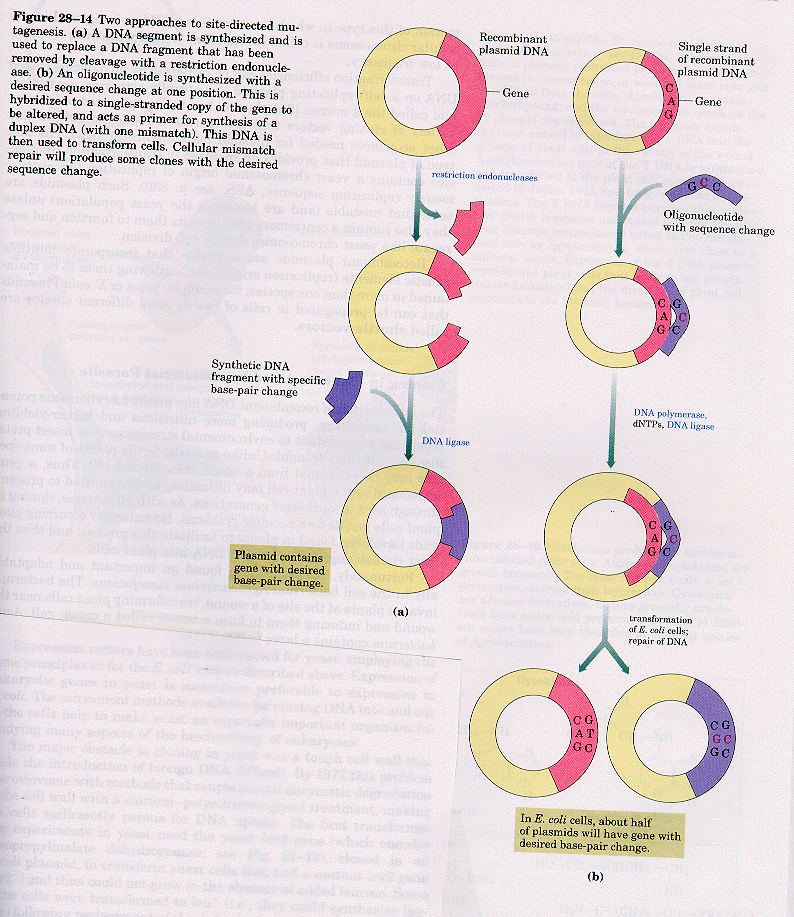
Using recombinant DNA technology, the gene that encodes the protein can be altered at one or more nucleotide, in a way which would either change one or more amino acids, or add or delete one or more amino acids. This technique, called site-specific mutagenesis, is used extensively by protein chemist to detemine the importance of a given amino acid in the folding, structure, and activity of a protein. The techniques is described in the diagram below;
FIGURE: SITE SPECIFIC MUTAGENESIS - LEHNINGER, PG 1001, FIG 28-14
E. Searching DNA
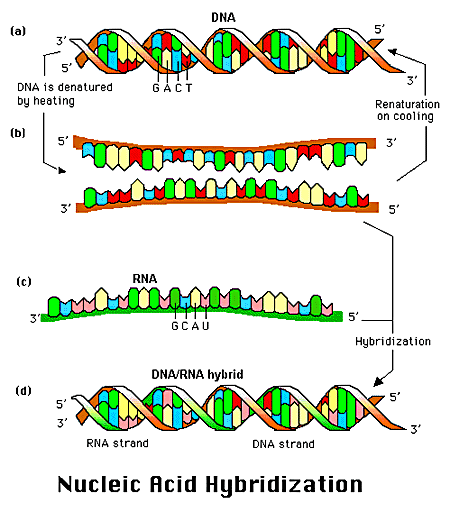
Where on a chromosome is the gene that codes for a given protein? One way to find the gene is to synthesize a small oligonucleotide "probe" which is complementary to part of the actual DNA sequence of the gene (determined from previous experiments). Attach a fluorescent molecule to the DNA probe. Then take a cell preparation in which the chromosomes can be seen under the microscope. To the cell add base which unwinds the double stranded DNA helix, add the fluorescent probe to the cell, and allow double stranded DNA to reform. The fluorescent probe will bind to the chromosome at the site of the gene to which the DNA is complementary, as shown below.
FIGURE: LOCATION OF GENE ON A CHROMOSOME - STRYER, FIG 6-10, PG 125
An example of a DNA-RNA complex is shown below.
F. COMPARING DNA
The DNA sequence of each individual must be different from every other individual in the world (with the exception of identical twins). The difference must be less than the difference between a human and a chimp, which are 98.5 % identical. Let us say that each of have DNA sequences that are 99.9 % identical as compared to some "normal human". Given that we have about 4\3 billion base pairs of DNA, that means we are all different in about 0.001 x 3,000,000,000 which is about 3 million base pairs different. This means that on the average we have one nucleotide difference for each 1000 base pairs of DNA. Some of these are in genes, but most are probably in between DNA, and many have been shown to be clustered in areas of highly repetitive DNA sequences at the ends of chromosomes (called the teleomers) and in the middle (called the centromers).
Now remember that their are restriction enzyme sites interspersed randomly along the DNA as well. If some of the differences in the DNA among individuals occurs within the sequences where the DNA is cleaved by restriction enzymes, then in some individuals a particular enzyme won't cleave at the usual site, but at a more distal site. Hence, the size of the restriction enzyme fragments should differ for each person. Each persons DNA, when cut by a battery of restriction enzymes, should give rise to a unique set of DNA fragments of sizes unique to that individual. Each persons DNA has a unique Restriction Fragment Length Polymorphism (RFLP). How could you detect such polymorphism?
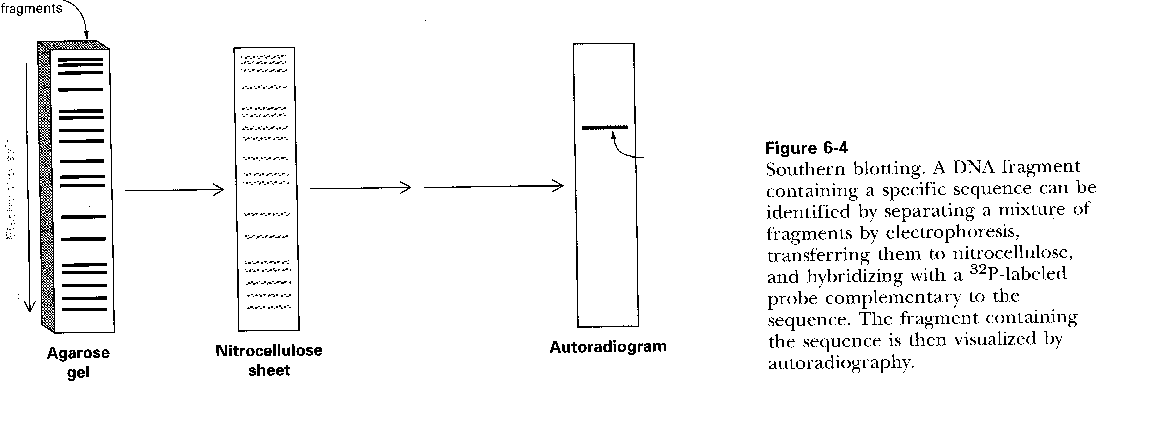
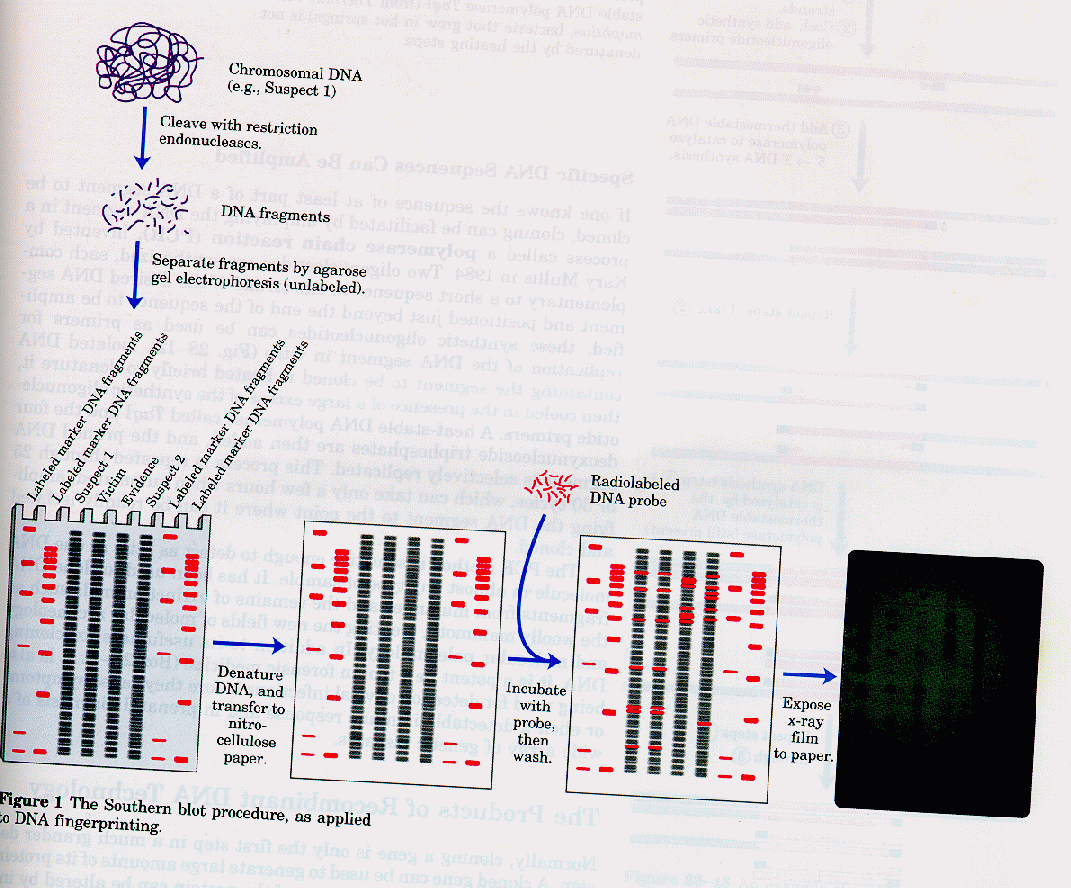
You already know how to cut sample DNA with restriction enzymes, and then separate the fragments on an agarose gel. An additional step is required, however, since thousands of fragments could appear on the gel, which would be observed as one large continuous smear. If however, each fragment could be reacted with a set of small, labeled DNA probes which are complementary to certain highly polymorphic sections of DNA (like teleomeric DNA) and then visualized, only a few sets of discrete bands would be observed in the agarose gel. These discrete bands would be different from the DNA bands seen in another individual's gene treated the same way. This technique is called Southern Blotting and works as shown below. DNA fragments are electrophoresed in an agarose gel. The ds DNA fragments are unwound by heating, and then a piece of nitrocellulose filter paper is placed on top of the gel. The DNA from the gel transfers to the filter paper. Then a small radioactive oligonucleotide probe, complementary to a polymorphic site on the DNA, is added to the paper. It binds only to the fragment containing DNA complementary to the probe. The filter paper is dried, and a piece of x-ray film is placed over the sheet. Also run on the gel, and transferred to the sheet, are a set of radioactive fragments (which are not complementary to the probe), which serve as a set of markers to ensure that the gel electrophoresis and transfer to the filter paper was correct. This technique is shown on the next page, along with a RFLP analysis from a particular family.
FIGURE: SOUTHER BLOT - STRYER, PG 121, FIG 6.4
When this technique is used in forensic cases (such as the OJ Simpson trial) or in paternity cases, it is called DNA fingerprinting. With present techniques, investigators can state unequivocally that the odds of a particular pattern not belong to a suspect are in the range of one million to one. The x-ray film shown below is a copy of real forensic evidence obtained from a rape case. Shown are the Southern blot results from suspect 1, suspect 2, the victim, and the forensic evidence. Analyze the data.
G. Single Nucleotide Polymorphisms (SNPs) and differences in humans:
SNPs are single bases in the DNA that differ in at least 1% of the population. They occur about every 1250 bases. Recent work show they are mostly in non protein-coding regions of the genome (in regions of DNA between the genes and in introns) Venter has shown that "more than 99% of human SNPs are not associated with biology. Only 2000 SNPs change an amino acid sequence of a regulatory site. That is a few thousand out of 2-3 million SNPs cataloged so far." If they occur in gene, they may not lead to change in the amino acid sequence of a resulting protein. (Example: CCA in mRNA to CCG both give the amino acid Pro in the protein). All the emerging DNA analyses suggest that Homo Sapiens arose form one common ancestor inn Africa about 200,000 years ago and people migrated out of Africa around 125,000 years ago. Observed difference in people emerged just recently. There is, in fact, no genetically pure population (in contrast to Arian mythology). .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}