Structure of a chromosome
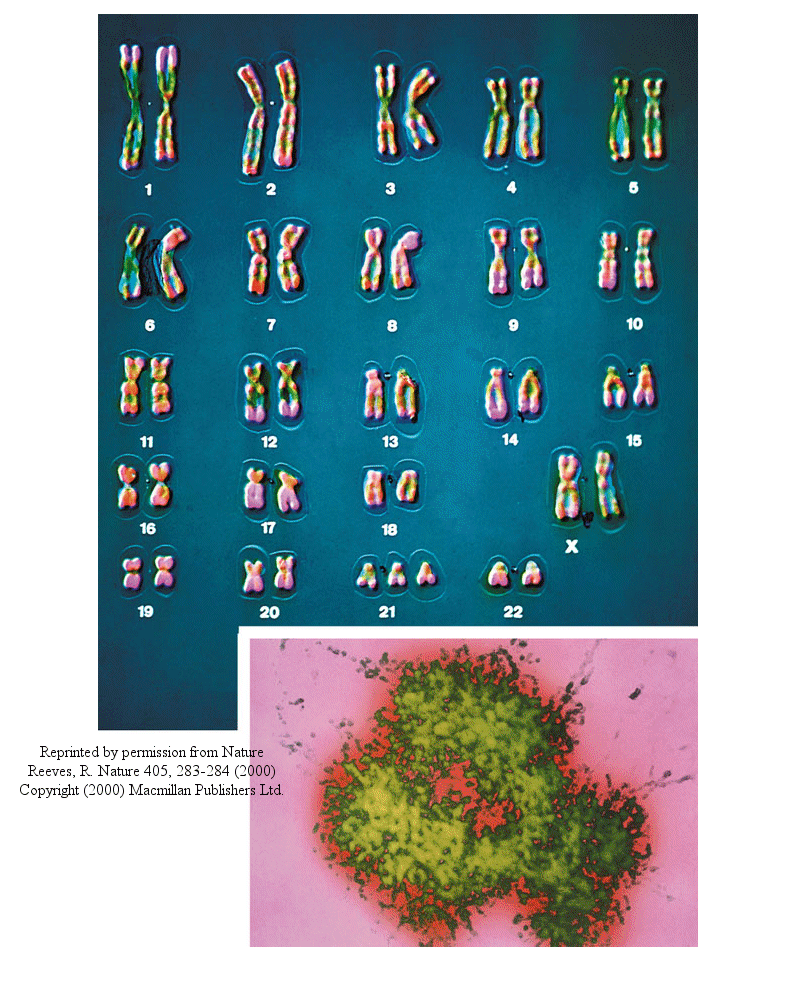
Most people have seen pictures of chromosomes viewed through microscopes. Check out this amazing picture of a chromosome taken form Scientific American, September, 1995.
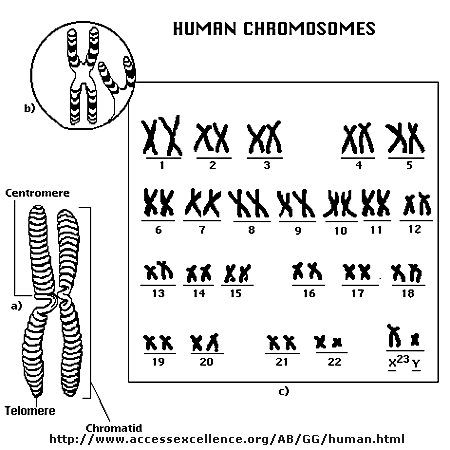
Chromosomes consist of one dsDNA molecule. Each somatic (body) cell of your body has 23 pairs of chromosomes, one member of each pair contributed by your mother and the other by your father. (In germ cells - eggs and sperm - there are 23 individual chromosomes, not chromosome pairs.) One pair are the sex chromosomes, which can come in two forms, X and Y. A pair of X's gives a female, and an XY results in a male.
Human Chromosomes (with an extra copy of Chromosome 21, which causes Down syndrome
The human genome has about 3 billion base pairs of DNA. Therefore, on average, each single chromosome of a pair has about 150 million base pairs, which consists of one molecule of DNA and lots of proteins bound to it. dsDNA is a highly charged molecule, and can be viewed, to a first approximation, as a long rod-like molecule with a large negative. charge. This very large molecule must somehow be packed into a small nucleus. The packing problem is solved by coiling DNA and packing it with proteins, which usually have a net positive charge. The chromosomes are usually dispersed within the nucleus and are not visible with an ordinary microscope. When the cell is ready to divide, the DNA in the chromosomes replicates, and the chromosomes condense in a fashion that they are visible (when stained) using an ordinary microscope. At this point the chromosomes can be stained with a variety of stains (hence the name chromosomes), some of which bind differentially to different chromosomes. The different chromosomes can hence be distinguished by their size, shape, and dye-binding properties.
The standard picture of a chromosome with which you are familiar, including the one shown above, is actually one chromosome of a pair that has just replicated!. One of the chromosomes will stay will the mother cell, and the other will go to the daughter cell. These two chromosomes which are aligned and appear joined at their centers are called sister chromatids. These large DNA/protein complexes must be further packaged in the nucleus, as shown in the "Carl Saganesque" reducing view of the chromosome, a double stranded DNA molecule winds around a core of proteins.
Fun DNA Facts to Know and Tell
Central Dogma of Biology:
DNA is the carrier of genetic information in organisms. What does that mean? Large molecules in organism can have many functions: they can provide structure, act as catalyst for chemical reactions, serve to sense changes in their environment (leading to immune responses to foreign invaders and to neural responses to stimuli such as light, heat, sound, touch, etc) and provide motiliy. DNA really does none of these things. Rather you can view it as an information storage system. The information must be decode to allow the construction of other large molecules. The other molecules are usually proteins, another class of large polymers in the body. Chromosomes are located in the nucleus of a cell. DNA must be duplicated in a process called replication before a cell divides. The replication of DNA allows each daughter cell to contain a full complement of chromosomes.
Animation of Replication: requires Hypercosm plugin (available when select link)
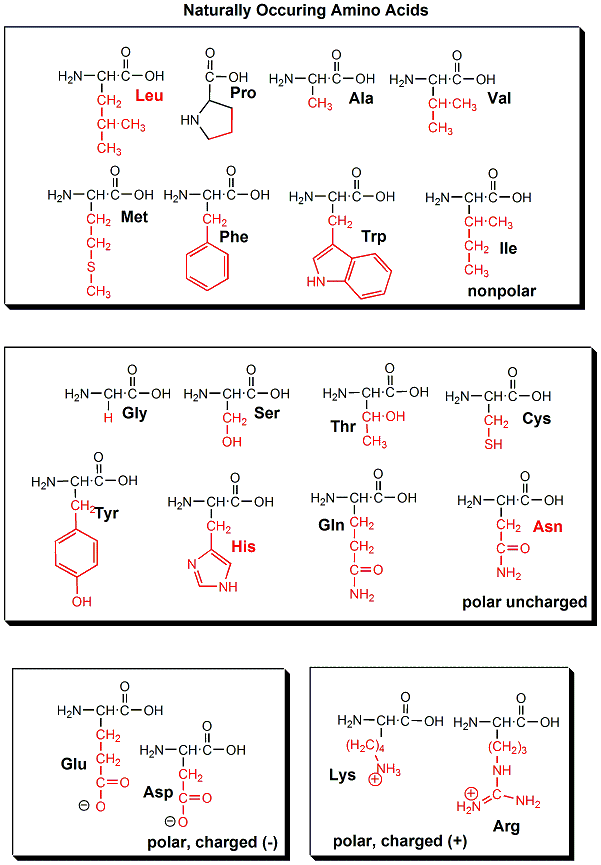
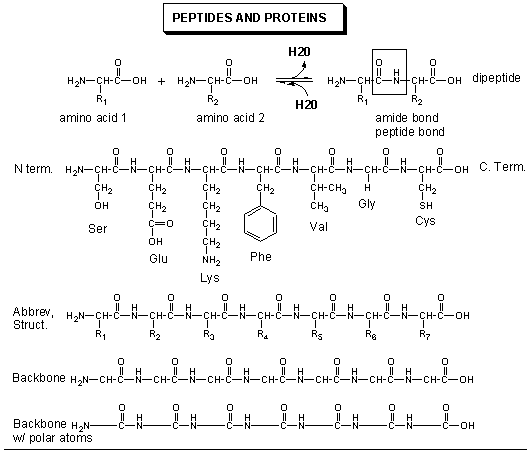
The actual information in the DNA of chromosomes is decoded in a process called transcription through the formation of another nucleic acid, ribonucleic acid or RNA. The RNA, made by the enzyme RNA polymerase, is complementary to one strand of the DNA. RNA differs from DNA in that RNA contains a ribose, not deoxyribose, sugar in its backbone. In addition, RNA lacks the base T. It is replaced, instead, with the base U, which is complementary to A (as T is complementary to A in DNA). The RNA formed acts as a messenger, which passes from the nucleus into the cytoplasm of the cell. In fact, this type of RNA is often called messenger RNA, mRNA. The information from the DNA, now in the form of a linear RNA sequence, is decoded in a process called translation, to form a protein, another biological polymer. The monomer in a protein is called an amino acid, a completely different kind of molecule than a nucleotide. There are twenty different naturally occurring amino acids that differ in one of the 4 groups connected to the central carbon. In an amino acid, the central (alpha) carbon has an amine group (RNH2), a carboxylic acid group (RCOOH), and H, and an R group attached to it. With four different groups attached to the central carbon, all amino acis (except Glycine) are chiral and exists in enantiomers or mirror image forms. Only one of the mirror image is found in proteins.
20 Naturally Occuring Amino Acids - Molecular Models: Notice the common blue and red groups in al amino acids. Notice the different "R" groups pointing down in each figure.
The monomers come together to form a long chain called a protein. The linear sequence of a protein can be depicted in many ways, as shown below.
In contrast to the complementarity of DNA and RNA (1 base in RNA complementary to 1 base in DNA), there is not a 1:1 correspondence between a base (part of the monomeric unit of RNA) in RNA to the monomer in a protein. After much work it was discovered that a contiguous linear sequence of 3 nucleotides in RNA is decoded by the molecular machinery of the cytoplasm with the result that 1 amino acid is added to the growing protein. Hence a triplet of nucleotides in DNA and RNA have the information for 1 amino acid in a protein. That there was not a 1:1 correspondence between nucleotides in nucleic acids and amino acids in proteins was evident long ago since there are only 4 different DNA monomers (with A, T, G, and C) and 4 different RNA monomers (with A, U, G, and C) but there are 20 different amino acid monomers that compose proteins.
Now, it turns out that not all the information in the DNA sequence of a organism encodes for a protein. In fact only about 2% of the 3 billion base pairs seem to be transcribed into RNA which can be translated into protein. The function of the rest of the DNA is at present uncertain. How does the molecular machinery of the cell know which part of the DNA encodes for proteins. It turns out that there are unique DNA sequences at the beginning and end of the part of the DNA sequence that codes for a protein. Proceed down the DNA of a chromosome and suddenly you come to those signals, which are recognized by the cells machinery. A complementary RNA is made from that section, and the complementary RNA is then decoded into a single protein. Continue further down the DNA sequence and another such coding sequence is found, which can be transcribed into a mRNA, which then can be translated into another unique protein. In all there are about 30-40 thousand such sections of DNA in all the chromosomes that encode the information for 30-40 thousand unique proteins. These unique coding sections of DNA that ultimately are transcribed into unique mRNA which are translated into unique proteins are called genes. For our purposes, we conclude that one gene has the information for one protein. Each of the protein differ from each other in both length, and the specific sequence of amino acids in the protein. The DNA is indeed the blueprint of the cell. What determines the actual characteristics of the cells are the actual proteins that are made by the cell.
Not only must DNA be transcribed into DNA, but the genetic information in the DNA must be replicated before a given cell divides, so that the daughter cells both contain the same genetic information. In replication, the dsDNA separate, and an enzyme, DNA polymerase, makes complimentary copies of each strand. The two resulting dsDNA strands separate to different daughter cells during division. The process where by DNA is replicated when cells divide, and is transcribed into RNA which is translated into protein is called the Central Dogma of Biology. (disregard tRNA, rRNA, and snRNA in the preceding web link)
As mentioned above, each amino acid is specified by a particular combination of three nucleotides in RNA. The three bases are called a codon. The Genetic Code consists of a chart which shows what triplet RNA sequence or codon in mRNA codes for which of the 20 amino acids. One of the codon codes for no amino acids and serves to stop the synthesis of the protein from the mRNA sequence. The genetic code is shown below:
GENETIC CODE
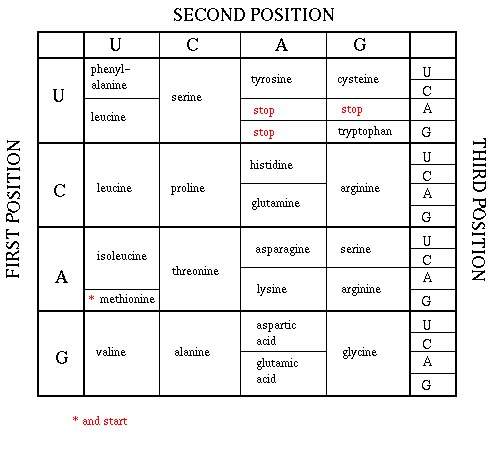
Determining the protein sequence from a DNA sequence.
For a given gene, only one strand of the DNA serves as the template for transcription. An example is shown below. The bottom (blue) strand in this example is the template strand, which is also called the minus (-) strand,or the sense strand. It is this strand that serves as a template for the mRNA synthesis. The enzyme RNA polymerase sythesizes an mRNA in the 5' to 3' direction complementary to this template strand. The opposite DNA strand (red) is called the coding strand, the nontemplate strand, the plus (+) strand, or the antisense strand.
The easiest way to find the corresponding mRNA sequence (shown in green below) is to read the coding, nontemplate, plus (+), or antisense strand directly in the 5' to 3' direction substituting U for T. Find the triplet in the coding strand, change any T's to U's, and read from the Genetic Code the corresponding amino acid that would be incorporated into the growing protein.
5' T G A C C T T C G A A C G G G A T G G A A A G G 3' 3' A C T G G A A G C T T G C C C T A C C T T T C C 5'
5' U G A C C U U C G A A C G G G A U G G A A A G G 3'
A Nucleotide to Protein Converter
Proteins
In contrast to the linear polymers of DNA and RNA, proteins (linear polymers of amino acids) fold in 3D space to form structures of unique shapes. Each unique protein sequence (of a given length and sequence of amino acids) folds to a unique 3D shape. Hence there are about 30-40 thousand proteins of different shapes in humans. Not only do proteins have unique shapes, but they also have unique nooks and crannies and pockets which allow them to bind other molecules. Binding of other molecules to proteins or DNA initiates or terminates the function of the protein or nucleic, much like an on/off switch. The example below show different protein structures, some of which have small molecules or large molecules (like DNA) bound to them. Some common motiffs are found within the 3D structure of the protein. The include alpha helices and beta sheets. These are held together by H-bonds between the slightly positive H on the N in the protein backbone and a slightly negative O further away on the protein backbone. In the Chime models below, use the mouse controls to rotate the molecule. (Also shift L-mouse click will change the size of the molecule). Click on the command in the right hand frame to change the rendering of the proteins. The cartoon view allows a simple way to interpret the overall structure of the main chain.
Mutations
If the DNA sequence in a coding region becomes changed, the resulting mRNA will also be changed, which will lead to changes in the protein sequence. These changes might have no effect and be silent, if the change in the protein does not affect the folding of the protein or its binding to another important molecule. However, if the changes affects either the folding or the binding region, the protein may not be able to perform its usual function. If the function was to put on break on cell division, the result might lead the cell to become a cancerous. Likewise, if the normal protein had a role in causing the cell to die after its intended life span, the cell with the mutant protein might not die and more likely become a tumor. The opposite scenarios could happen leading the cell to a premature death.
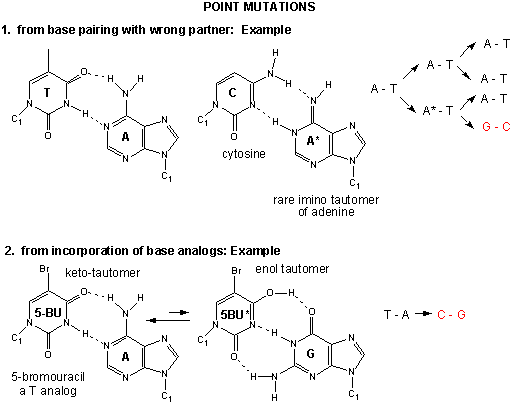
Point mutations: From bad luck and nucleotide analogs
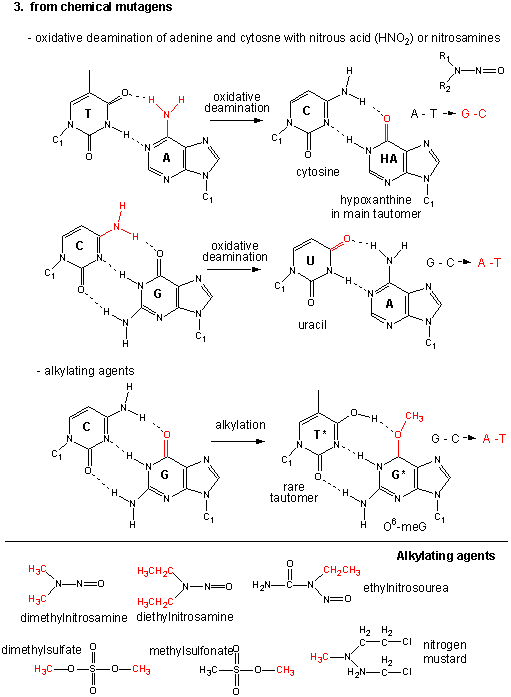
Point mutations: From chemical mutagens
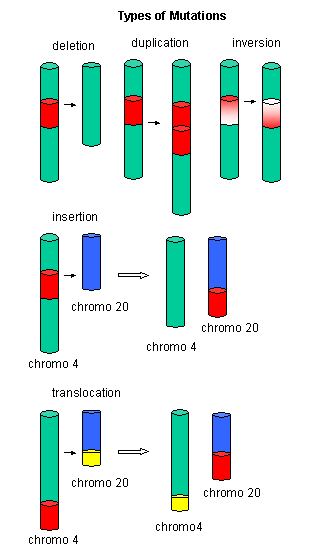
Large mutations: Deletions, insertions, duplications, and inversions
Genes and Disease
A Map showing gene involvement in specific human diseases. Click on the chromosome number.
Homework: Find a gene associated with a specific chromosome. Identify the protein and report the location of the gene in the chromosomes.
Protein-Molecule Interactions
You will now view interactive displays of proteins interacting with molecules like DNA and drugs using Chime. The interactions between drugs and proteins are mediated by intermolecular forces (like H bonds, etc) t
![]() 1.
Protein: Antiviral Drug Complex: 1HSG: Crystal structure at 1.9-A
resolution
of human immunodeficiency virus (HIV) II protease complexed with L-735,524,
an orally bioavailable inhibitor of the HIV proteases.
1.
Protein: Antiviral Drug Complex: 1HSG: Crystal structure at 1.9-A
resolution
of human immunodeficiency virus (HIV) II protease complexed with L-735,524,
an orally bioavailable inhibitor of the HIV proteases.
![]() 2.
Protein:DNA Complex: A bacterial virus (lambda) and an inhibitor protein
2.
Protein:DNA Complex: A bacterial virus (lambda) and an inhibitor protein
![]() 3.
Structural basis for
inhibition of the Hsp90 molecular chaperone by the antitumor antibiotics
radicicol. The Hsp90 molecular chaperone is a protein that helps
other proteins to fold to their correct state.
3.
Structural basis for
inhibition of the Hsp90 molecular chaperone by the antitumor antibiotics
radicicol. The Hsp90 molecular chaperone is a protein that helps
other proteins to fold to their correct state.
![]() 4.
Binding of the leech protein
hirudin to thrombin, the blood clotting protein. Chain I is the hirudin
protein found in the saliva of leeches. The hirudin molecule is a small protein that lies in a
grove in thrombin, preventing thrombin from clotting blood.
4.
Binding of the leech protein
hirudin to thrombin, the blood clotting protein. Chain I is the hirudin
protein found in the saliva of leeches. The hirudin molecule is a small protein that lies in a
grove in thrombin, preventing thrombin from clotting blood.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}