Biochemistry Online: An Approach Based on Chemical Logic
CHAPTER 5 - BINDING
D: BINDING AND THE
CONTROL OF GENE
TRANSCRIPTION
BIOCHEMISTRY - DR. JAKUBOWSKI
Last Updated: 03/30/16
|
Learning Goals/Objectives for Chapter 5D: After class and this reading, students will be able to
|
D15. ENCODE: Encyclopedia of DNA Elements
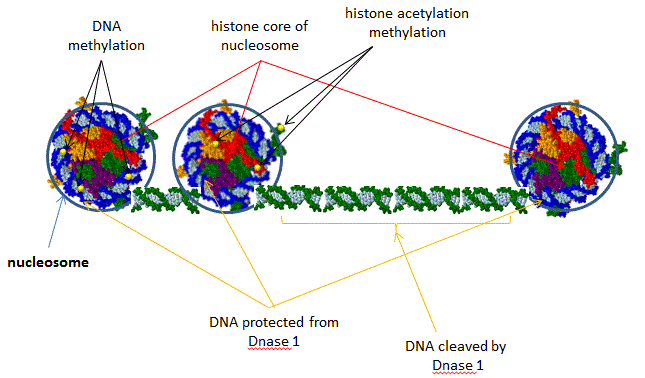
ENCODE is a public research consortium, sponsored by the National Human Genome Research Institute (NHGRI), who goals is to identify all functional elements in the human genome sequence. In September 2012, scientists involved in the project simultaneously published multiple papers the have significantly altered our understanding of how information about gene regulation is encoded into the genome. Scientists have now identified how function is encoded into most of the genome, a far cry from the early notion that nonprotein-coding DNA sequences, which comprise 98% of the genome, is irrelevant or junk DNA. Investigators used a variety of techniques to link structure to specific regions of the genome including sequencing of transcribed RNA from different types of cells, assessing senstivity/protection of DNA to an endonuclease, DNase 1, which gives information on DNA packing in chromatin and accessibility to transcription factors (see figure below), and mapping long range effects of distal enhancers on gene transcription,.
Figure: DNase 1 Sensitivity of Nucleosome Bound and Free DNA
Here are some of the consortium's significant findings:
-
80% of the genome contains sequences linked to function;
-
The space between coding sequences contains a multitude of enhancer, promoters and sites of non-protein coding RNA transcription, many of which are in DNA regions shown to be involved in disease;
-
75% of DNA is transcribed during the life of the cell with transcription occurring from both strands and often overlapping;
-
Large numbers of DNase 1 sensitive sites map to experimental and theoretical sites for transcription factor binding;
-
A large number of sites correspond to motifs involved in DNA protein binding;
-
More than 1000 different distal sequences occur in any cell which affect gene transciption adding great complexity to the simple notion that binding of proteins at the promoter and proximal response elements controls gene transcription;
-
Cells have more than 200,000 DNase 1 sensitive site (far more than the number of promoter sites)
-
About 400,000 regions display "enhancer-like" properties and 70,000 display "promoter-like" properties;
-
Although transcription factors usually bind to under-methylated DNA, transcription factor binding was also found to inhibit methylation;
-
Regulation of transcription involves both binding of protein as well as RNA transcribed from non protein-coding regions of the DNA.
-
Evolutionary mutations in DNA regulatory sequences have potential evolutionary advantage over those in protein-coding sequences since regulatory effects on gene transcription are cell and time dependence, allowing changes in only certain cells at certain times compared to changes in a coding sequence which could affect many different cells times at many times.
-
Different RNA transcripts vary one million fold in their expression level.
This list clearly shows that genetic information encoded by the linear sequence of DNA ("1 bit" per 3.2 billion base pairs) is only a first approximation of the available information which is encoded by small contiguous stretches of DNA (as found in promoters), by loops distal to promoters (enhancers), chemical modification of DNA (methylation) and DNA binding proteins (methylation, acetylation, phosphorylation), and accessibility of DNA sequences to transcriptional regulators (RNA, protein) and packaging proteins (histones). All of these must be considered as we try to decode the human genome.
Just as a contrast, we have already discussed how proteins also have additional information elements other than their primary sequence which has the information necessary for protein folding. Short linear stretches of amino acids also act as signaling elements. These included N-terminal signal sequences which help locate proteins in the outside of the cell, degradation sequences (regions enriched in PEST amino acids - single letter code), signals that have evolved to encourage or discourage homodimer, heterodimer or nonspecific aggregation, as well as sequences that lead to specific post-translational modifications. Biological macromolecules (proteins and nucleic acids) are surely information macromolecules.
 Navigation
Navigation
Return to Chapter 5D: Binding and the Control of Gene Transcription
Return to Biochemistry Online Table of Contents
Archived version of full Chapter 5D: Binding and the Control of Gene Transcription

Biochemistry Online by Henry Jakubowski is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.